
PDF編集豆知識
- 2 Mac/WinでPDF編集
PDFファイルで英文を翻訳機にかけたいが、20~30年前の部品のデータシータで何かスキャンナーからこのデータシート資料を取り込んだらしく、文字が画像として認識されずテキストをコピペすることができないです。
または、スキャナーで読み込んだ韓国語のPDFファイルをテキスト化して翻訳などしたいが、PDF ファイルからテキストを抜き出すことができないです。
このような場合には、スキャンナーで作成したいPDFファイルからテキストを抽出できるソフトをお探しているでしょう!
実は、スキャンナーで作成したPDFからテキストを抽出できるPDFelementをおすすめします。
OCR機能付きでスキャンされた画像ベースのPDFをテキストベースのWordやExcel、PowerPoint、EPUB、HTML、およびテキスト文書に保存できます。


PDFからテキストを抽出する方法
準備することとして、上記の「無料お試し」ボタンをクリックして、PDFelementをダウンロードし、お使いのパソコンにインストールします。
ステップ1.PDFelementにPDFファイルを追加
PDFelementのインストールが終わったら、起動させます。ソフトにPDFファイルを追加するには、直接にソフトへPDFファイルをドラッグしますか、または「PDFファイルを追加」ボタンをクリックし、PDFファイルをインポートすることができます。
ステップ2.OCR機能を有効化
スキャンされたPDFファイルをソフトに追加したら、下記の図面が現れます。この時には、OCR機能を有効化する必要があります。「ドキュメントの言語」から「日本語」を選択し、日本語版のOCRをダウンロードします。OCR機能をダウンロードし、インストールしてから、ソフトを再起動する必要があります。
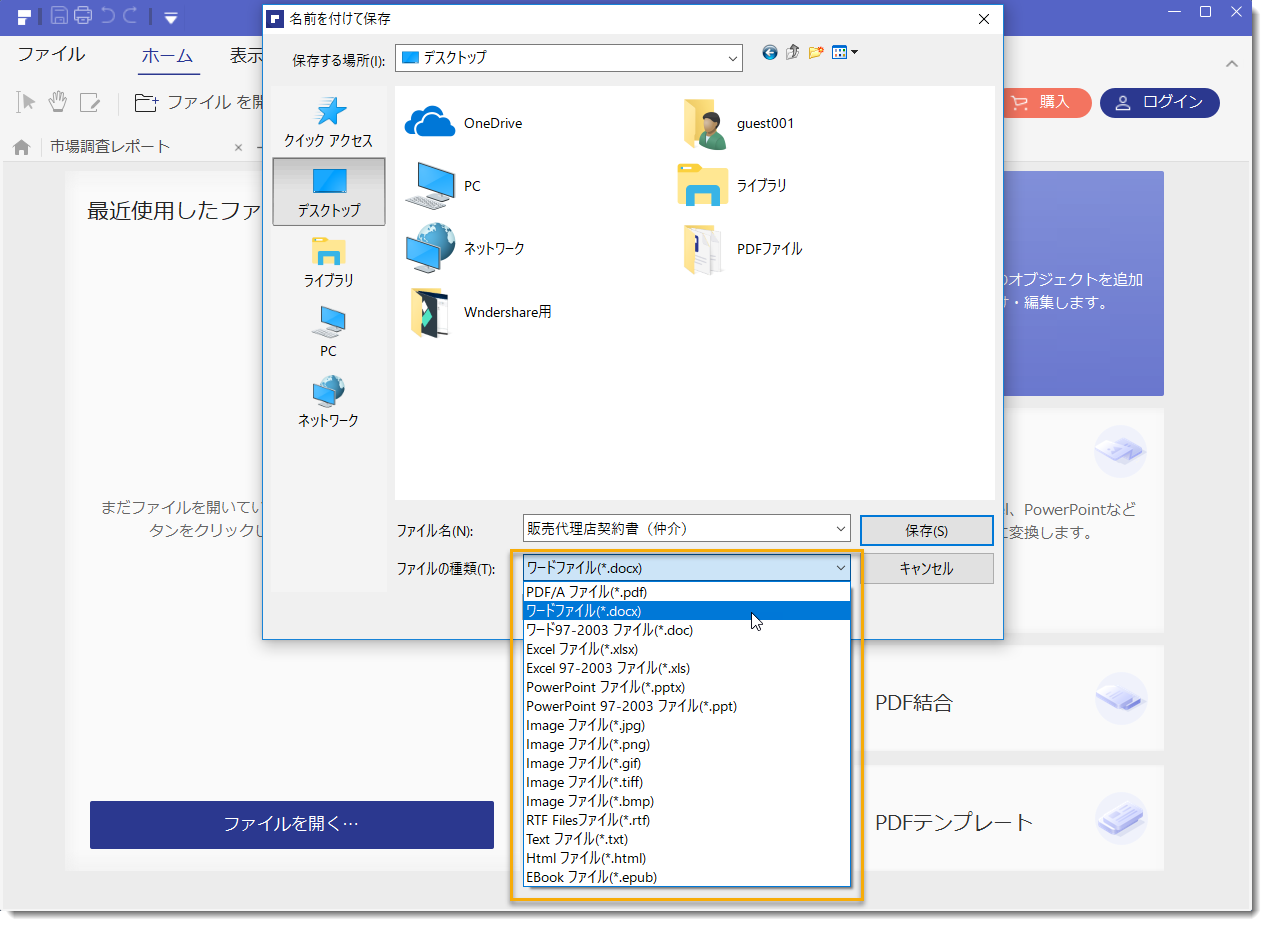
ステップ3.PDFをwordに変換
「出力フォーマット」から「Microsoft Excel」を選択し、出力フォルダに変換されたPDFを置く場所を選択できます。そして、「変換開始」ボタンをクリックします。
ステップ4.PDFから文字を抽出
選択されたフォルダから変換されたwordからテキストを抽出できます。
PDFからテキストを抽出するフリーソフトPDFelementで簡単にPDFからテキストを抽出することができます。


木村秀雄
編集
0 Comment(s)